



文字轉圖像界又出新工具!這次的主角是 Google Brain 推出的 Imagen,再一次突破人類想像力,將文字轉圖像的逼真度和語言理解提高到前所未有的新高度!比前段時間 OpeAI 家的 DALL·E 2 更強!
話不多說,我們來欣賞這位AI畫師的傑作:

▲ A dragon fruit wearing karate belt in the snow.(在雪地裡戴著空手道腰帶的火龍果。)(Source:Google,下同)

▲ A marble statue of a Koala DJ in front of a marble statue of a turntable. The Koala has wearing large marble headphones.(戴著巨大耳機的無尾熊DJ大理石雕像站在一個大理石轉盤前。)

▲ An art gallery displaying Monet paintings. The art gallery is flooded. Robots are going around the art gallery using paddle boards.(陳列莫內畫作的美術館淹水了,機器人正在使用槳板在美術館裡划船。)

▲ A giant cobra snake on a farm.The snake is made out of corn(農場裡有一根巨大玉米構成的眼鏡蛇。)

▲ Teddy bears swimming at the Olympics 400m Butterfly event.(泰迪熊在奧運400公尺蝶泳項目中游泳。)
以及更多……


相同的文字提示,Imagen也可以產生不同類別的圖像。比如下面這些圖中,各組圖片在物品的顏色、空間位置、材質等範疇上都不太相同。
Imagen的工作原理
Imagen的可視化流程
Imagen基於大型transformer語言模型在理解文本方面的能力,以及擴散模型在產生高畫質圖像方面的能力。
在用戶輸入文本要求後,如「一隻戴著藍色格子貝雷帽和紅色圓點高領毛衣的金毛犬」,Imagen先是使用一個大的凍結(frozen)T5-XXL編碼器將這段輸入文本編碼為嵌入。然後條件擴散模型將文本嵌入映射到64×64的圖像中。
Imagen進一步利用文本條件超解析度擴散模型對64×64的圖像進行升採樣為256×256,再從256×256升到1,024×1,024。結果表明,帶噪聲調節增強的級聯擴散模型在逐步產生高畫質圖像方面效果很好。

▲ 輸入「一隻戴著藍色格子貝雷帽和穿著紅色圓點高領毛衣的黃金獵犬」後Imagen的動作。

▲ 64×64產生圖像的超解析度變化。對於產生的64×64圖像,將兩種超解析度模型分別置於不同的提示下,產生不同的升採樣變化。
大型預訓練語言模型×級聯擴散模型
Imagen使用在純文字語料中進行預訓練的通用大型語言模型(例如T5),它能夠非常有效地將文本合成圖像:在Imagen中增加語言模型的大小,而不是增加圖像擴散模型的大小,可以大大地提高樣本畫質和圖像─文本對齊。
Imagen的研究突出體現在:
- 大型預訓練凍結文本編碼器對於文本到圖像的任務來說非常有效。
- 縮放預訓練的文本編碼器大小比縮放擴散模型大小更重要。
- 引入一種新的閾值擴散採樣器,這種採樣器可以使用非常大的無分類器指導權重。
- 引入一種新的高效U-Net架構,這種架構具有更高的計算效率、更高的記憶體效率和更快的收斂速度。
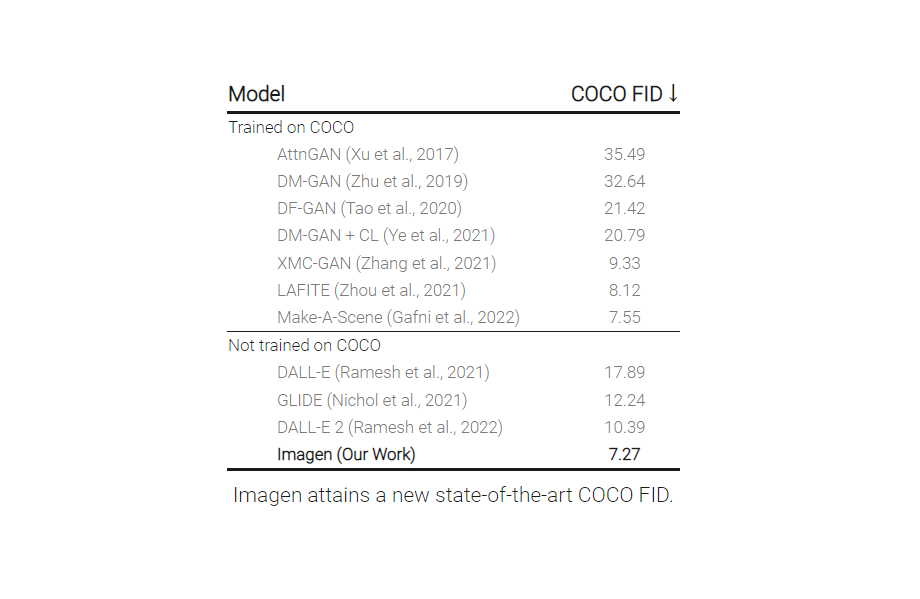
- Imagen在COCO數據集上獲得了最先進的FID分數7.27,而沒有對COCO進行任何訓練,人類評分者發現,Imagen樣本在圖像-文本對齊方面與COCO數據本身不相上下。
引入新基準DrawBench
為了更深入地評估文本到圖像模型,Google Brain引入了DrawBench,這是一個全面的、具有挑戰性的文本到圖像模型基準。藉由DrawBench,他們比較了Imagen與VQ-GAN+CLIP、Latent Diffusion Models和DALL-E 2等其他方法,發現人類評分者在比較中更喜歡Imagen而不是其他模型,無論是在樣本質量上還是在圖像─文本對齊方面。
- 並排人類評估。
- 對語意合成性、基數性、空間關係、長文本、生詞和具有挑戰性的提示幾方面提出了系統化的考驗。
- 由於圖像─文本對齊和圖像保真度的優勢,相對於其他方法,用戶強烈傾向於使用Imagen。

▲ Imagen與DALL-E 2、GLIDE、VQ-GAN+CLIP和Latent Diffusion Models在DrawBench上的比較:用戶對圖像─文本對齊和圖像逼真度的偏好率(95%置信區間)。
Imagen與DALL-E 2產生圖像的比較圖例:

▲ 「外星人綁架乳牛,將其吸入空中盤旋」(上);「一個被貓絆倒的希臘男性雕塑」(下)。
對於涉及顏色的文本提示,Imagen產生的圖像也比DALL-E 2更優。DALL-E 2通常很難為目標圖像分配正確的顏色,尤其是當文本提示中包含多個對象的顏色提示時,DALL-E 2會容易將其混淆。

▲ Imagen和DALL-E 2從顏色類文字轉圖像的比較。「一本黃色書籍和一個紅花瓶」(上);「一個黑色蘋果和一個綠色雙肩包」(下)。
而在帶引號文本的提示方面,Imagen產生圖像的能力也明顯優於DALL-E 2。

▲ Imagen和DALL-E 2從帶引號文字轉圖像的比較。「紐約天空上有煙火寫成的「Hello World」字樣」(上);「一間寫著Time to Image的店面」(下)。
打開了潘朵拉盒子?
像Imagen這樣從文字轉圖像的研究面臨著一系列倫理挑戰。
首先,文本─圖像模型的下游應用多種多樣,可能會從多方面對社會造成影響。Imagen以及一切從文字轉圖像的系統都有可能被誤用的潛在風險,因此社會要求開發方提供負責任的原始碼和展示。基於以上原因,Google決定暫時不發布程式碼或進行公開展示。而在未來的工作中,Google將探索一個負責任的外部化框架,進而將各類潛在風險最小化。
其次,文本到圖像模型對數據的要求導致研究人員嚴重依賴於大型的、大部分未經整理的、網路抓取的數據集。雖然近年來這種方法使演算法快速進步,但這種性質的數據集往往會夾帶社會刻板印象、壓迫性觀點、對邊緣群體有所貶損等「有毒」資訊。
為了去除噪音和不良內容(如色情圖像和「有毒」言論),Google對訓練數據的子集進行過濾,同時Google還使用了眾所周知的LAION-400M數據集進行過濾對比,該數據集包含網路上常見的不當內容,包括色情圖像、種族主義攻擊言論和負面社會刻板印象。Imagen依賴於在未經策劃的網路規模數據上訓練的文本編碼器,因此繼承了大型語言模型的社會偏見和局限性。這說明Imagen可能存在負面刻板印象和其他局限性,因此Google決定,在沒有進一步安全措施的情況下,不會將Imagen發布給大眾使用。





