



強大、公開且夠簡單的模型,最近很紅的 Stable Diffusion 在文字產生圖像以外也有無限創作性,最近 Lambda Labs 機器學習研究員 Justin Pinkney 微調模型,做出精靈寶可夢產生器。
下圖是輸入戴珍珠耳環的少女、歐巴馬、川普、強生、龍貓、Hello Kitty後產生的寶可夢:

Lady Gaga、強生、普丁、梅克爾、川普、柏拉圖:

(Source:The Verge)
耶穌:
Jesus Christ as a Pokemon, via Pokemon-finetuned Stable Diffusion pic.twitter.com/4mtsq6In9k
— Max Woolf (@minimaxir) September 20, 2022
除了常見角色和公共人物,還能輸入文字描述產生想像的寶可夢,如骷髏祭司:

(Source:The Verge)
也可輸入姓名或帳號名,產生自己的寶可夢形象。網友紛紛用自己的名字試驗,看自己如果是寶可夢會長什麼樣子。
網友 Jo Barf Creepy 是寶可夢的話:
I made AI generated Pokémon with my Twitter handles. I’M OBSESSED.
Harpie’s Slut → harpie’s slut → harpie’s 𝖘𝖑𝖚𝖙
Jo Barf Creepy → jo barf creepy → jobarfcreepy pic.twitter.com/pAv0wTADK5
— harpie’s 𝖘𝖑𝖚𝖙 (@jobarfcreepy) September 26, 2022
網友 Upbeatblue 是寶可夢的話:
This is me https://t.co/zsk6JKh2Wo pic.twitter.com/2zi7wfq89W
— Upbeatblue (@blue_upbeat) September 29, 2022
網友 Onion-sama 是寶可夢的話:
This is my username in the generator
Actually kind of looks like an onion princess. https://t.co/gcQLXrDPt2 pic.twitter.com/k1rSQLvcXK
— Onion-sama (@HimeOnion) September 29, 2022
陪我們長大的皮卡丘、妙蛙種子、噴火龍、樹才怪、路卡利歐、夢幻經過產生器也變成新模樣:

(Source:TechCrunch)
寶可夢產生器如何「產生」
Pinkney 展示寶可夢產生器的訓練過程。Stable Diffusion 是很好用的通用模型,但要穩定輸出特定風格不容易,通常要大量枯燥步驟,製作複雜文字提示庫,或也能偷懶只微調圖像產生模型。Pinkney 用寶可夢圖片資料庫微調原始 Stable Diffusion 模型。
首先構建資料庫,含寶可夢圖片和文字描述,如妙蛙種子是「紅眼睛的綠色神奇寶貝圖」,綠毛蟲為「有紅鼻子的綠色黃色玩具」。
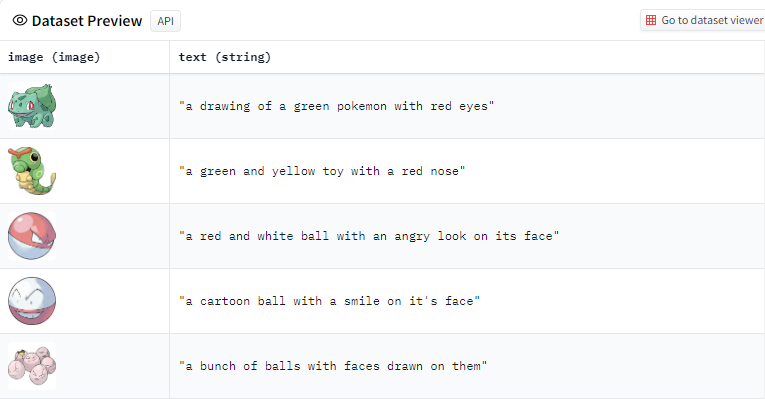
▲ 寶可夢資料庫。
當然文字描述也不是人工輸入,而是用神經網路代勞,即圖像描述模型 BLIP。這些文字還不完美,但也夠用。然後他在 A6000 只花幾小時訓練 AI 模型,學習以寶可夢風格產生圖片,但保留知識一段時間,最後過擬合資料庫。
開始樣本為正常圖像,逐漸學得寶可夢風格,訓練越多,就會呈現與原始提示不同的寶可夢:

微調很簡單,但執行起來效果非常好,微調模型訓練好後,無論給什麼提示,都會產生新寶可夢。所以不必煞費苦心創作了,需要新寶可夢時,只要選擇輸出多個:

▲ 有翅膀的機械貓。
Pinkney 表示,歡迎大家複雜使用模型於新領域,這種小工具就是 Stable Diffusion 這類 AI 模型開源的優點。
One more thing
這模型引發熱潮後,Pinkney 又在部落格補充細節。
他發現,模型竟然記住原始 Stable Diffusion 的通用知識,但它只是用有限資料庫訓練了幾千步的模型。微調寶可夢時模型很快會過擬合,如果只以簡單方式採樣,模型就會產生胡言亂語式寶可夢,也就是說,災難性遺忘訓練的原始資料庫。但 Stable Diffusion 訓練期間保持模型指數移動平均(EMA)版本,通常是推理用。
如果使用 EMA 權重,其實是用原始模型和微調模型的平均值。事實證明,這對產生寶可夢不可或缺。還能直接平均新模型與原始模型權重以微調,控制產生寶可夢的數量。微調和平均可將原始內容與微調風格有效混合。

▲ 左邊是完全微調,右邊是只微調注意力層。
也能凍結模型不同部分微調,如上圖是兩種微調效果,只微調注意力層模型產生更正常的尤達大師,但不太擅長創造新寶可夢。
(本文由 雷鋒網 授權轉載;首圖來源:Justin Pinkney)





