



到底需不需要向量資料庫(Vector Database),好像又變成問題了。
一年前OpenAI拿出ChatGPT大手一揮,奧特曼(Sam Altman)成了〈回到未來〉背後的羅伯·辛密克斯,AGI廣告牌突然踏進滾滾紅塵,沾上喜氣的萬物開始生長,也包括向量資料庫這半新不舊的概念股。開始冠上「AI時代技術基底」的概念,變成Pinecone、Chroma和Weviate等向量資料庫新創上半年融資進展,有的融資額高達上億美元。
幾個月後,AI時代還沒到來,OpenAI就親手澆熄了火苗。
爭議
剛散場的第一屆OpenAI開發者大會,每句話都奉若圭臬。歷史重演猝不及防,大家都害怕了。
1879年洛帕克街第一次電燈點亮時愛迪生那件大衣你錯過了,2007年拿著初代iPhone時賈伯斯身上三宅一生高領毛衣你錯過了,現在Sam Altman純色針織衫總不能再錯過了吧?
後驗歷史脈絡這次還沒發生前就把「第N次工業革命」、「下個iPhone時刻」的時間點告訴你了。第一屆OpenAI開發者大會門檻比柏林Berghain還高。Altman用GPTS潑了追著他創業又好不容擠進去的應用開發者一盆冷水,又拿著叫Assistants的API朝擠不進去的向量資料庫開發者潑另一盆水。
Assistants API允許開發者在應用程式建立Al助理,支援解碼器、檢索和函數呼叫三類工具。OpenAI「檢索」解釋是,如果有資料庫可直接扔進來,會自動最佳化數據,也就是向量化,然後原地後續儲存和處理。
有手快開發者已試過並判斷說現在GPTS有種沒用向量資料庫的感覺,但長久下去,Assistants API更完整後就沒必要另外用其他向量資料庫處理數據了。如果最終開發者還是要經ChatGPT開發應用。
什麼是向量資料庫?
向量資料庫的數據以向量形式儲存和處理,需將原始非向量資料轉成向量。資料向量化是指將非向量型資料轉為向量的過程,透過資料向量化後就可高效率相似性計算和查詢。
向量資料庫概念相對於傳統關係型資料庫,兩者有結構化和非結構化資料概念。如在Word找一詞,網路書店找某作者所有書,就是結構化程度非常高的資料。關鍵字、指標、字串和JSON都是高度結構化類型。
但現實更混亂。現代人可能一個月看不完一本書,但每天可在網路瀏覽50篇文章開頭,加上仔細研究Facebook、X或Reddit貼文,加上各種通訊軟體聊天。相對一板一眼的紙書,大部分資訊來自雜七雜八的資訊網。零碎化,代表結構化程度非常低,難以找到關連。
再延伸,文字本就是世界訊息的壓縮。從世界接收的所有訊息,文字分量微不足道,大部分訊息是以畫面(圖片、影片)或聲音等更直覺形式呈現。聊天紀錄、圖片或影片就是非結構化資料。統計顯示,非結構化資料佔全世界資料總量不斷上升,2025年將達八成。
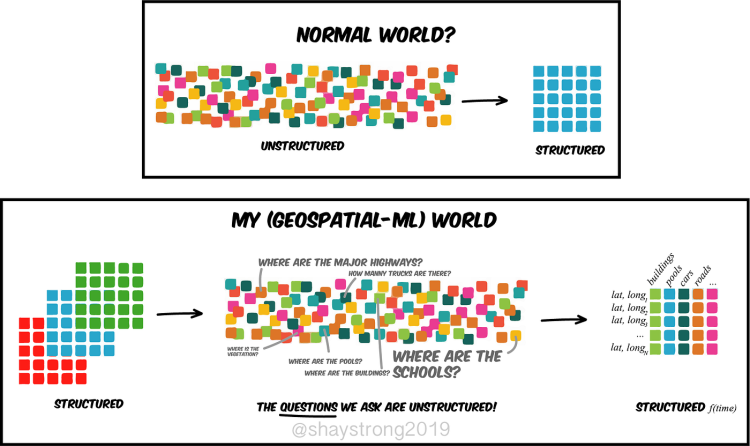
資訊爆炸的年代,不只燒腦,也燒AI。向量資料庫就是要為非結構化資料建立連結,並儲存下來。
「狡猾」的OpenAI
回到GPTS,Assistants API的意思不是向量資料庫不重要,更像說向量資料庫本身不是目的。OpenAI討論的是位置問題。原本向量資料庫可靠LandChain等中間體搭建,現在過程由ChatGPT完成,減少操作步驟,對開發者來說,資料向量化門檻降低不少。
但OpenAI仍有狡猾那面。公開的大模型訓練資料會越來越少,大量碰不到的資料存在各公司保險箱裡,或更零散存在個人使用者資料無法離境的社群平台。Altman看起來願意多走一步,野心可能是為了讓你多走一步──分享你的數據。當然這只是揣測,但很多公司不買帳,仍想要確保資料安全的中立向量資料庫。
分層
從GPTS開始,向量資料庫出現新趨勢。最初向量資料庫從大模型中間層竄出,如上半年拿到熱錢的Chroma和Qdrant,然後像OpenAI掌握大模型轉至應用程式終端的公司,開始把向量資料庫放上檯面,另一派是從雲端服務切入探索向量資料庫。
有趣現象是,全世界有做資料庫的公司都在美國和中國,但有明顯世代差距。美國資料庫產業重心已是非結構化資料,中國還以結構化資料為主;前者建立在更完善的開源生態上,中國以商業資料庫為多。
生成式AI是全球競爭,資料庫是基礎要素。追趕下塑造技術領域,首先需要產業發展標準,近日中國信通院與大數據研究所聯合騰訊、阿里巴巴等50家企業專家設定的標準《向量資料庫技術要求》,含基本功能、維運管理、安全性、相容性、擴展性、高可用及工具生態七大能力域共47個測試項目,分成27個必選項和20個可選項。算是業界首個向量資料庫標準,可為向量資料庫研發、測試及選型提供參考。
首批「可信任資料庫」向量資料庫產品測試中,騰訊雲向量資料庫Tencent Cloud VectorDB成為第一個通過基準測試的向量資料庫產品。C端業務寬而厚實的騰訊要怎麼做向量資料庫,可為中國向量資料庫發展的參考。
樣本
下圖展示騰訊雲向量資料庫架構。

API 層:允許與其他軟體元件互動。使用者透過這層與向量資料庫互動,有Web控制台,使用者可直接管理資料庫;軟體開發工具包(SDK),支援多種程式語言,讓應用程式直接整合資料庫功能
Compute Layer(計算層):負責處理資料和執行,包括多種資料庫操作,如 Upsert(更新或插入)、Delete(刪除)、Update(更新)、Query(查詢)、KNN(最近鄰搜尋)、Range(範圍查詢)、Filter(過濾),還有 AI 操作如Embedding、Split、Index Training。
Storage Layer(儲存層):負責資料持久化與儲存,有RocksDB資料庫(一個鍵值儲存),以Raft協定確保多副本一致性,每副本分成Leader和Follower。還有搜尋和索引,如HNSW、IVF、反向索引(Inverted Index)及對象儲存(支援 pdf、word、txt 等檔案格式)。
向量資料庫不是最終目的地
通常向量資料庫只專注儲存和檢索向量數據,準備(如向量化)和索引訓練往往在資料庫以外應用程式或服務負責。騰訊雲向量資料庫直接將Embedding整合進運算層。加上KNN和Index Training,可能比其他向量資料庫更緊密,提供點到點資料處理和機器學習,使用者可用資料庫模型訓練和向量化,無需靠外部工具。
如果把現在OpenAI看成以GPTS為主的公司,選擇將向量資料庫功能收進末端應用程式,以雲端廠商視角看,本來就離用戶原始資料更近,資料向量化是雲端服務框架下的概念。還是那句話,向量資料庫不是最終目的。
騰訊雲選擇包辦向量化過程(Embedding),並當成獨立產品推出,減少用戶將數據從一系統(如數據處理或機器學習平台)轉至另一個系統(如向量資料庫)。單一系統做完工作,也可提高效率並減少錯誤。使用者資料保護顧慮,可交給私有化部署。
資料庫不是開發完成,是使用完成
這框架使用多種索引結構,如HNSW和IVF。HNSW(Hierarchical Navigable Small World)是基於圖片的索引法,創建多層級圖結構,近似最近鄰搜尋能以較低成本快速執行,尤其高維度空間。即便高度複雜資料庫也能提供高品質搜尋結果。
IVF(Inverted File Index)是量化索引法,透過量化向量空間減少儲存需求並加速搜尋。由於IVF可將向量空間量化成較小編碼,大大減少儲存需求,也更適合大規模資料庫。且可透過尋找預先計算的量化中心減少比較向量數,IVF提供速度優勢。
複合索引結構在需快速回應時間和高精確度的應用程式非常有效,如影像辨識、推薦系統和線上廣告。資料庫不是開發完成,是使用完成。這種索引結構的組合也反映了騰訊雲向量資料庫獨特的生長脈絡。
騰訊雲向量資料庫2019年開始孵化,2020年接入騰訊音樂、騰訊視頻和QQ瀏覽器等產品,現在騰訊雲向量資料庫服務騰訊業務數量達40多個,日請求量有1,600億次。近日騰訊第三季財報,廣告業務營收年增20%,騰訊也提到AI相關技術的貢獻。
AI筆記本
2015年Google嘗試用RankBrain將純文字轉成「詞向量」開始,資料向量化優越性更明顯,向量資料庫角色不會太快消失。資料庫演化代表人類刻畫世界資訊的能力更進步,只要完全駕馭AI,AI進步就還是建立在人類如何理解和記憶世界資訊邏輯基礎上。向量資料庫是提供AI記憶能力的海馬迴,但AI遠比人類自由,海馬迴的位置和形態可不斷改變。就像人類最初在大腦外的「海馬迴」可能只是筆記本,到現在變成筆電。
(本文由 品玩 授權轉載;首圖來源:shutterstock)





