



為了在人工智慧領域取得更強大的競爭優勢,Google 正在組建 AI 產業界最具多樣性的客製化晶片供應鏈。此舉也被市場視為 Google 針對輝達(Nvidia)在 AI 推論(Inference)領域主導地位所發起的最直接、最具規模的挑戰。
這項戰略規劃於 Google Cloud Next 大會前夕曝光,揭示 Google 將與博通(Broadcom)、聯發科(MediaTek)、美滿電子(Marvell)以及英特爾(Intel)四大設計夥伴展開深度合作,並由台積電負責製造代工。這份藍圖不僅涵蓋了目前已出貨數百萬顆的推論晶片,更延伸至預計於 2027 年底部署,採用台積電 2 奈米製程的 TPU v8 晶片。
這項硬體戰略的核心是 Google 的第七代 TPU 「Ironwood」,這同時也是 Google 首款專門為「推論」工作負載所設計的晶片,其在規格表現上,Ironwood 展現了強悍的實力。其最高效能是上一代 TPU v5p 的十倍,每顆晶片配備高達 192 GB 的 HBM3E 記憶體,記憶體頻寬更達到每秒 7.2 TB。
此外,這款晶片能夠擴展至由 9,216 顆液冷晶片組成的超級叢集(Superpod),提供高達 42.5 FP8 exaflops 的強大算力。 目前,Ironwood 已全面開放給 Google Cloud 的客戶使用。Google 計劃在 2026 年內生產數百萬顆 Ironwood 晶片。其中,知名 AI 新創公司 Anthropic 已承諾採用高達 100 萬顆 TPU,而 Meta 也與 Google 達成了相關的租賃協議。
四大合作夥伴分進合擊,台積電統包代工 Google 的晶片計畫透過精細的專業分工,將產品線交由不同的設計夥伴負責,藉此分散風險並提升談判籌碼:
一、博通(Broadcom):
作為高效能晶片的主力合作夥伴,博通在 2026 年 4 月 6 日與 Google 簽署了一項長達至 2031 年的協議,負責供應 TPU 與網路元件。博通目前正致力於設計代號為「Sunfish」的下一代 TPU v8「訓練 (Training)」晶片,目標是鎖定在 2027 年底採用台積電的 2 奈米製程。目前博通在客製化 AI 加速器市場中占據了超過 70% 的絕對領先地位。
二、聯發科(MediaTek):
台灣 IC 設計大廠聯發科則負責操刀成本最佳化的推論版 TPU v8,代號為「Zebrafish」,同樣瞄準 2027 年底的台積電 2 奈米製程。聯發科最初是參與 Ironwood 的 I/O 模組與周邊元件設計,其提供的設計方案比市場其他替代方案便宜了 20% 至 30%。透過讓博通負責訓練晶片、聯發科負責推論晶片的「雙軌並行」策略,Google 成功掌握了供應鏈間的平衡與議價優勢。
三、美滿電子(Marvell):
Google 目前正與 Marvell 洽談開發記憶體處理單元(Memory Processing Unit)以及一款新的推論專用 TPU。若雙方順利簽約,Marvell 將成為第三家晶片設計夥伴。Google 預計將生產近兩百萬顆記憶體處理單元,相關設計預計於 2027 年正式定案。
四、英特爾(Intel):
英特爾於 4 月 9 日與 Google 達成了一項多年期協議,將為 Google 的 AI 資料中心基礎設施供應 Xeon 處理器及客製化基礎設施處理單元(IPU)。這項合作主要涵蓋 TPU 周邊的網路設備與通用運算層,而非 AI 加速器核心本身。
在晶片製造端,台積電扮演了不可或缺的角色。台積電是 Google 客製化晶片的唯一代工廠。所以,無論是哪一家夥伴設計的晶片,最終都將交由台積電的晶圓廠進行生產,形成緊密的結構性合作關係。
「推論經濟學」使 Google 將重心從「訓練」轉向「推論」,這是其整個晶片計畫背後最關鍵的戰略前提。訓練一個先進 AI 模型是一個單次且高度密集的事件。然而,「推論」卻是持續不斷的,它會隨著每位使用者、每一次查詢以及每一個整合 AI 的產品而無限疊加。Google 每天必須處理數十億次由 AI 驅動的搜尋查詢、Gemini 對話以及 Cloud AI API 呼叫。在如此龐大的規模下,單次推論的成本將直接決定整個 AI 商業模式的經濟效益。
儘管輝達的 GPU 在模型訓練領域依然占據絕對優勢(主要受惠於其 CUDA 生態系所建立的極高轉換成本),但推論工作通常更具可預測性及重複性,這正是客製化晶片(ASIC)進行固定功能最佳化最能發揮所長的地方。只要一款專為推論打造的客製化晶片,其單次查詢成本能低於輝達 GPU,就算它的多功能性不如 GPU,也能在 Google 所追求的規模經濟指標上獲得勝利。為了確保持續領先,Google 刻意建立備援機制,同時投資多條推論晶片路線(從 Ironwood 到 Zebrafish 及 Marvell 的潛在晶片),以避免過度依賴單一供應商所帶來的定價風險與產能危機,並確保自家的 AI 發展藍圖不被他人掌控。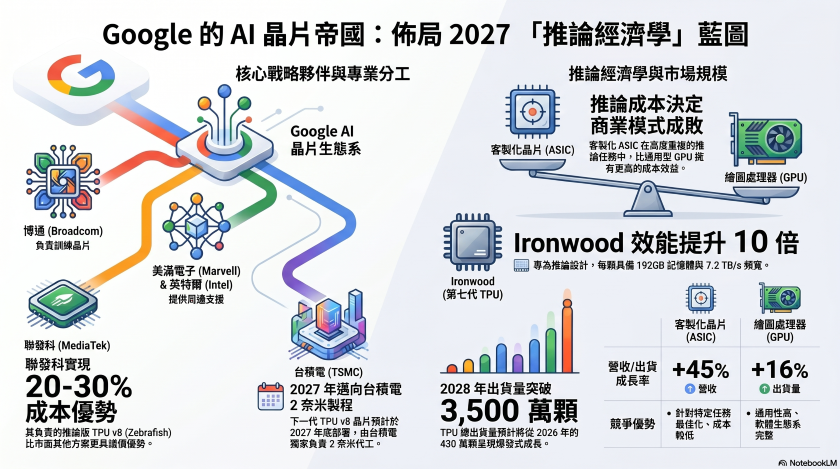
市場野心與未來展望 Google 的龐大野心已反映在其驚人的出貨量預測上。預期其 TPU 總出貨量將在 2026 年達到 430 萬顆,並在 2028 年快速攀升至超過 3,500 萬顆。從全球市場趨勢來看,客製化 ASIC 市場的成長速度正在超越 GPU 領域。另外,根據市場研究機構 TrendForce 預測,2026年客製化晶片營收將大幅成長 45%,而 GPU 出貨量則僅成長 16%;整個 ASIC 市場預計將在 2033 年達到 1,180億 美元的驚人規模。
面對 Google 步步進逼的挑戰,輝達面臨的威脅並非來自某款單一晶片的效能超越,而是 Google 正在打造一個由多款針對特定任務與成本最佳化的晶片所組成的龐大系統」這個系統將集體壓縮輝達硬體在 Google AI 運算中的占比。輝達的應對策略則是反向滲透,例如透過投資 Marvell 20 億美元及推廣 NVLink Fusion 計畫,確保即便在被 ASIC 逐漸取代的機架中,仍能保留一席之地。
總結來說,Google 正透過掌控自身橫跨多個合作夥伴與多個世代的晶片供應鏈,試圖在 AI 推論領域創造出能隨時間產生複利效果的成本優勢。雖然輝達的霸主地位難以在短期內被徹底撼動,但在大規模推論的經濟效益上,這條由四大巨頭共同支撐的硬體供應鏈,已成為 Google 捍衛自身 AI 帝國、強化競爭力的最強大武器。
(首圖來源:Google)





