



自 NVIDIA 的圖靈(Turing)架構問世已過了一個多月,GeForce RTX 20 系列發表及即時光線追蹤技術,讓 NVIDIA 將使用多年的「GeForce GTX」更名為「GeForce RTX」,並徹底改變遊戲顯卡。即時光線追蹤、RT Core、Tensor 核心、AI 功能(即 DLSS)、光線追蹤 API,所有匯集在一起,為遊戲開發和 GeForce 顯卡的未來發展指明新方向。
與過去產品大不相同,NVIDIA 已將最新顯卡的介紹內容分為兩部分:架構和效能。近日,NVIDIA 終於揭開全新圖靈架構細節的面紗,雖然一些有趣處未有官方解釋,還有一些環節需要與客觀資料一起深入研究,但也讓我們有機會深入了解為 GeForce RTX 冠名的技術:光線追蹤。

雖然使用圖靈的即時光線追蹤功能需要借助 DirectX 光線追蹤(DXR)API、NVIDIA 的 OptiX 引擎或未發表的 Vulkan 光線追蹤延伸,用於遊戲的 DXR 還沒推給終端機用戶,但鑑於 NVIDIA 傳統具有開發人員和中介軟體(如 GameWorks)的強大生態系統,他們希望利用高階遊戲來激發消費者支持混合算圖(光域化+光線追蹤)。
正如之前所說,NVIDIA 透過混合算圖努力推動消費級 GPU 達成轉變。使 NVIDIA 邁出這步的背後原因,撇開「即時光線追蹤是電腦圖形學的聖杯」這點之外,還有很多超越圖形純粹主義的其他潛在動機。
光線追蹤第一課:what & why
由於 NVIDIA 光線追蹤的 RT Core 是圖靈架構的兩項技術基石之一,因此深入了解圖靈架構之前,最好先討論清楚什麼是光線追蹤,以及為什麼 NVIDIA 會投入如此多晶片資源。
簡而言之,光線追蹤是一種計算繪圖方式,可模擬光在現實世界的表現(反射、折射等)。最大問題在於近乎無底洞一樣誇張的效能需求,如果使用最原始方法嘗試計算場景中每光源發出的所有光線,將會追蹤到無窮無盡的光線。

多年以來,演算法工程師為光線追蹤開發許多最佳化措施,其中最重要的是把「光照」簡單概念復原,不是從光源開始追蹤光線,而是從螢幕、從觀測者的視點逆向追蹤光線,這樣便可只計算實際到達螢幕的光線,大幅縮減所需的計算量。

然而即便使用此法在內的許多最佳化方式,光線追蹤對效能的需求依然高得驚人。除了最基本、最粗糙的光線追蹤,其他任何情況都超出即時計算繪圖的範圍。這些最佳化技術僅讓光線追蹤在電腦上以相對「合理」的時間完成,當然這個「合理」是以小時或天來衡量,這要取決於場景的複雜程度及期望達到的算圖效果。實際上到目前為止,光線追蹤一直被主要是 3D 動畫電影等場景「離線」使用。


光域化算圖的是是非非
光線追蹤的高成本意味著無法用於場景時影像計算著色,因此電腦業從一開始便使用名為光域化的算圖方法。
雖然名字有「光」字,但整個光域化算圖其實根本沒有「光線」概念。光域化(Rasterization)指的是 3D 幾何轉換為 2D 畫素的過程,所有畫面特效都只針對一個個畫素作業。
當遊戲開始計算繪製一格畫面時,首先由 CPU 生成遊戲場景所有物體頂點,然後把所有頂點座標資訊傳送給 GPU 內的幾何單元。幾何單元以螢幕位置為基準構建可視空間,將這些頂點按照座標安置到空間,緊接著將頂點連線成線框,構造出物體外框,然後在表面覆蓋一層帶有光照資訊的底層材質為蒙皮。到這步,遊戲畫面便初具幾何形態。
接下來便是整個光域化算圖流程的核心:光域化,GPU 內的光域化單元(Rasterizer)依照線透視關係,將整個可視空間從三維立體形態壓成一張二維平面。之後處理器再根據場景物體之間的幾何位置關係,透過各種算圖演算法,確定哪些畫素亮和有多亮,哪些畫素暗和有多暗,哪些畫素是打光,哪些畫素是陰影。
處理器忙著計算畫素資訊的同時,GPU 的材質單元也開始將預設的「整張」材質剪裁成畫面所需形狀。最後,處理器和材質單元分別把計算好的畫素資訊和剪裁好的材質遞交給 GPU 後端的 ROPs,ROPs 將二者混合填補為最終畫面匯出。除此之外,遊戲中霧化、景深、動態模糊和抗鋸齒等後處理特效,也是由 ROPs 完成。
看到這裡應該明白,我們看到的每格遊戲畫面,都是 GPU 畫給你的一張 3D 立體畫而已。3D 立體畫看起來真不真實,取決於繪畫者的水準如何;而光域化算圖的畫面真不真實,取決於算圖演算法是否先進完善。

混合算圖,光線追蹤回歸
光域化的簡單和快速決定了模擬現實世界畫面有限,這也導致光域化普遍有光照、反射和陰影不自然等缺陷。如果光域化如此不準確,遊戲如何進一步提高影像品質?
當然可以繼續這麼下去,光域化解決這些問題並非不可能,只是所需的計算效能會高速膨脹。就像撒一個謊要用十個謊來圓,某些情況下想用光域化算圖生成逼真畫面,甚至比光線追蹤的自然過程更複雜。
換句話說,與其在光域化這種本質是視覺欺騙的算圖方式消耗這麼多效能,何不把這些努力投入另一種可準確算圖虛擬世界的技術?
2018 年,整個電腦業都在思考這問題。對 NVIDIA 來說,前進的道路不再是純粹光域化,而是混合算圖:將光域化與光線追蹤相結合,是在有意義的地方使用光線追蹤──用於照明、陰影和其他所有涉及光的相互作用內容,然後使用傳統光域化處理其他,這正是圖靈架構的核心。

這意味著開發人員可以兩全其美,根據需求平衡光域化的高效能和光線追蹤的高品質,而無需立即從光域化跳到光線追蹤並失去前者的效能優勢。到目前為止,NVIDIA 及合作夥伴展示的案例都很容易實現,比如精確的即時反射和更好的全域光照,但顯而易見混合算圖可延伸到任何光照相關作業。
然而,NVIDIA、微軟和其他公司也不得不為從零開始建立新生態系統,不僅要向開發人員推銷光線追蹤的優點,還要教開發人員如何以有效的方式達成。
不過現在依舊可先討論一下光線追蹤,看看 NVIDIA 如何透過構建專屬硬體單元,將即時光線追蹤變成現實。

邊界體積層次結構
可以說,NVIDIA 在圖靈下了很大的賭注,傳統 GPU 架構可高速處理光域化算圖,但並不擅長光線追蹤。因此 NVIDIA 必須為光線追蹤增設專屬硬體單元,而這些其餘電晶體和電力消耗,卻對傳統的光域化算圖沒有直接幫助。
這部分專屬硬體單元很大程度用於解決光線追蹤的最基本問題:判定光線與物體的相交情況。這個問題最常見的解決方案是將三角形儲存在一個非常適合光線追蹤的資料架構,這種資料結構稱為 BVH(邊界體積層次)。

從概念上講,BVH 相對簡單,它並不是偵測每個多邊形以判斷是否與光線相交,而是偵測場景一部分檢視是否與光線相交。如果場景某部分與光線相交,則細分為較小部分並再次偵測,依次繼續下去直至單個多邊形,此時光線偵測得到解決。
對電腦科學家來說,這聽起來很像二元搜尋應用,確實如此。每次偵測都允許丟棄大量選項(光線追蹤中為多邊形)為可能答案,便可在很短時間內到達正確的多邊形。BVH 反過來又儲存本質是樹資料架構的東西中,每次細分(邊界框)都儲存為父邊線框的子節點。

現在 BVH 的問題是,雖然根本上減少了所需判斷的光線相交量,但這些都是針對單獨一條光線,當每個畫素需要多條光線經過時,每條光線都要大量偵測,計算量依然不低。這也是為什麼使用專門光線追蹤單元進行硬體加速如此重要。
繼承 Volta 精神的 Turing 架構
看看這次 Turing 架構,新 Turing SM 看起來與上一代 Pascal SM 非常不同,但了解 Volta 架構的人肯定會注意到 Turing SM 與 Volta SM 非常相似。
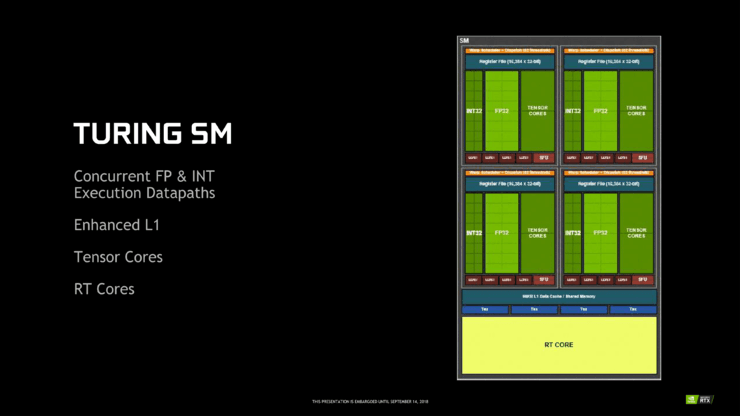
與 Volta 一樣,Turing SM 劃分為 4 個子核(或處理塊),每個子核有單個 warp 排程器和排程單元,而 Pascal 的 2 個割區設定是每個子核的 warp 排程器有兩個相對的排程通訊埠。
廣義上講,這樣的變化意味著 Volta 和 Turing 失去了在一個時鐘週期內從執行緒發出第二條非依賴指令的能力。Turing 可能與 Volta 在兩個週期內執行指令相同,但排程程式可以在每個週期發出獨立指令,因此 Turing 最終可透過這種方式維護雙向指令級並列(ILP),同時仍然具有兩倍於 Pascal 的排程程式數量。
正如 Volta 中看到的那樣,這些變化與新的排程/執行模型緊密相連,Turing 也有獨立的執行緒排程模型。與 Pascal 不同的是,Volta 和 Turing 都有每個執行緒的排程資源,有一個程式計數器和每個執行緒的堆疊來追蹤執行緒的狀態,以及一個收斂最佳化器,智慧將活動同 warp 執行緒分組到 SIMT 單元。
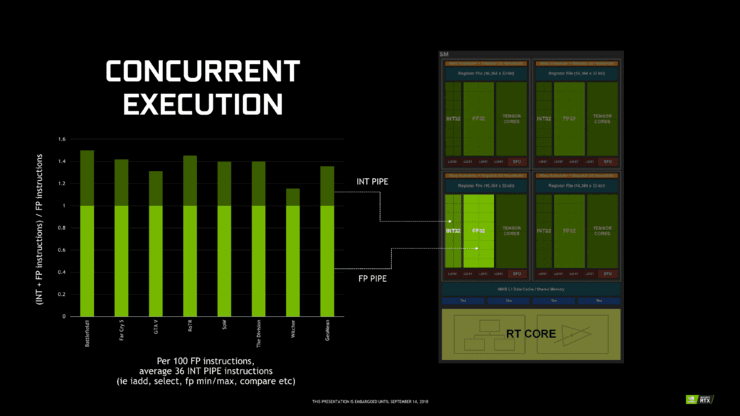
就 CUDA 和 ALU(算術邏輯單元)而言,Turing 子核有 16 個 INT32 單元,16 個 FP32 單元和 2 個 Tensor 單元,與 Volta 子核的設定相同。使用像 Volta 這種拆分 INT / FP 資料路徑模型,Turing 還可同時執行 FP 和 INT 指令,這與 RT Core 密切相關。Turing 與 Volta 的不同之處在於 Turing 沒有 FP64 單元,FP64 的吞吐量只有 FP32 的三十二分之一。
雖然這些細節可能更偏向於技術面,但 Volta 的設計似乎是為了最大化 Tensor Core 的效能,而最大限度減少破壞性並列性或與其他計算工作負載的協調。對 Turing 的第二代 Tensor Core 和 RT Core 來說情況也是如此,其中 4 個獨立排程的子核和粒度執行緒處理,對混合遊戲導向工作負載下達成最高效能非常有用。
記憶體方面,Turing 每個子核都有一個類似 Volta 的 L0 指令緩衝區,有相同大小的 64KB 暫存器檔案。Volta 中,這對減少 Tensor Core 延遲很重要,而 Turing 中這可能同樣有利於 RT Core。Turing SM 每個子核也有 4 個加載/儲存單元,低於 Volta 的 8 個,但仍然保持 4 個材質單元。
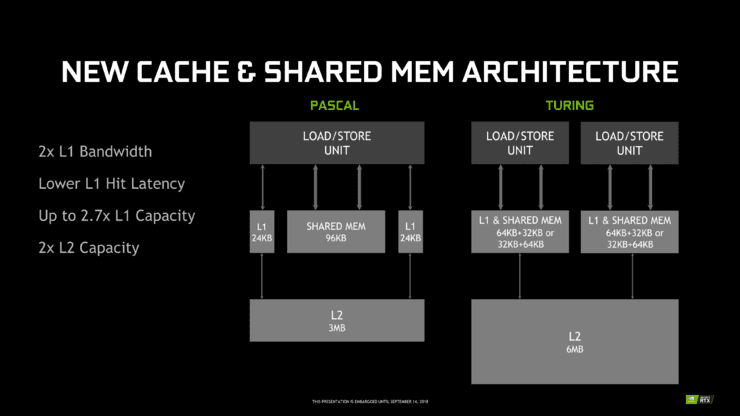
新的 L1 資料高速緩衝區和共用記憶體(SMEM)進一步向上延伸,被改進並統一為單個可割區記憶體塊,這是 Volta 的另一項創新。對 Turing 來說,這看起來是一個組合的 96KB L1 / SMEM,傳統圖形工作負載分為 64KB 專屬圖形著色器 RAM 和 32KB 材質高速緩衝區和暫存器檔案外溢區域。同時,計算工作負載可以將 L1 / SMEM 劃分最多 64KB 為 L1,其餘 32KB 為 SMEM,反之亦然(Volta 的 SMEM 最高可規格為 96KB)。
RT Core:混合算圖和即時光線追蹤
在圖靈,光線追蹤無法完全取代傳統的光域化算圖,而是當作「混合算圖」的一部分,且「即時」也只能在每個畫素只通過少量光線並輔以大量降噪的情況下做到。
出於效能原因,現階段開發人員有將意識和針對性的利用光線追蹤達成光域化無法做到的部分逼真效果,例如全域照明、環境光遮蔽、陰影、反射和折射等。光線追蹤同樣也可限於場景特定物件,並使用光域化和 z 緩衝代替主光線投射,而僅追蹤次光線。
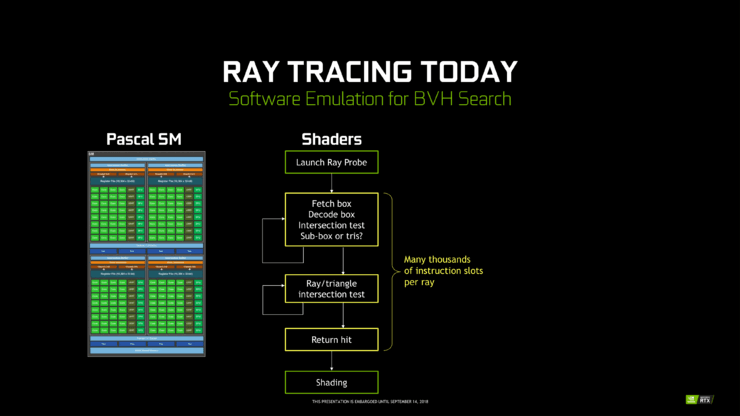
憑借光線追蹤在電腦圖形領域的重要性,NVIDIA Research 相當長一段時間內一直在研究各種 BVH,以及探索光線追蹤加速的架構問題。不過 NVIDIA 並未透露有關 RT Core 或 BVH 的許多細節。
RT Core 與 Tensor Core 不同,Tensor Core 更像與 FP 和 INT 核心一起的 FMA 陣列,而 RT Core 更像典型卸載 IP 塊。與子核中的材質單元非常相似,RT Core 的指令被路線到子核之外,從 SM 接收光線探測器後,RT 核心繼續自主遍歷 BVH 並執行光線相交偵測。
這種類別的「遍歷和交叉」固定函數光線追蹤加速器是眾所周知的概念,多年來已有很多實例,因遍歷和交叉偵測是計算密集程度最高的工作。相比之下,在著色器遍歷 BVH 需將每條光線投射數千個指令槽,所有這些都用於偵測 BVH 的邊界框交叉點。
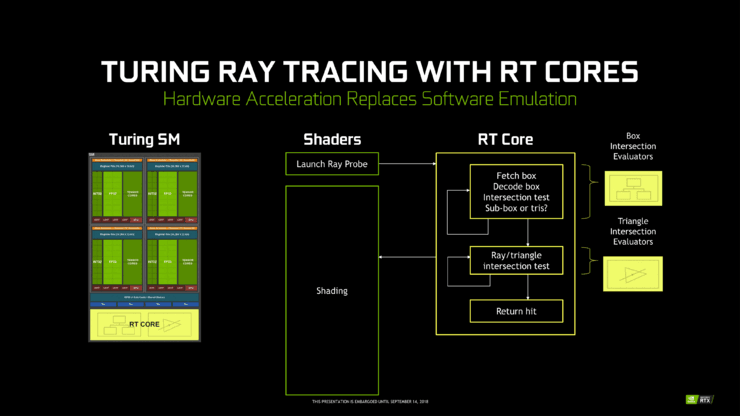
RT Core 還處理一些記憶體作業的分組和排程,以最大化跨多個光線的記憶體吞吐量。與許多其他工作負載一樣,記憶體頻寬是光線追蹤的一個常見瓶頸,也是 NVIDIA Research 多篇論文討論的焦點。考慮到光線追蹤會產生非常不規則和隨機的記憶體存取,SIP 塊可能還有一些記憶體和光線緩衝區。
Tensor Cores:將深度學習推理用於遊戲算圖
儘管 Tensor Cores 是 Volta 的典型特徵,但此番圖靈搭載的第二代 Tensor Core 卻青出於藍。
第二代 Tensor Core 的主要變化是增加推理用的 INT8 和 INT4 精度模式,透過新硬體資料路徑啟用,並執行點積累積為 INT32 積。INT8 的運算速度是 FP16 的 2 倍,或每個時鐘 2,048 次整數運算;INT4 的運算速度是 FP16 速率的 4 倍,或每個時鐘 4,096 次整數運算。
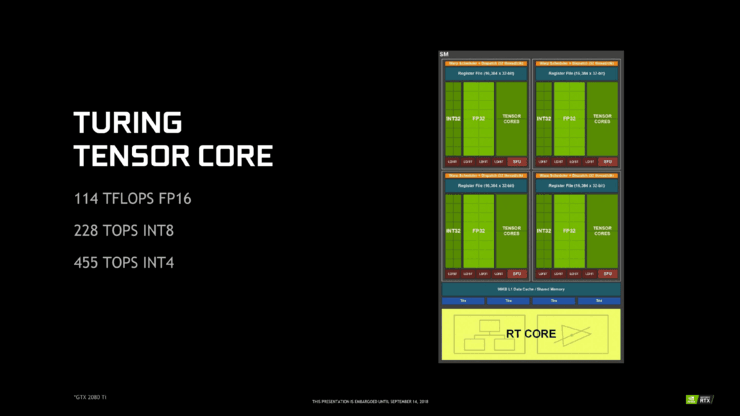
第二代 Tensor Core 仍有 FP16,並支援純 FP16 而沒有 FP32 累加器。雖然 CUDA 10 還沒有出來,但增強的 WMMA 作業應該能解釋任何其他差異,例如運算元的其餘可接受矩陣大小。
GeForce RTX 和圖靈帶來的不僅是 RTX 全新品牌命名,還有將圖靈所有功能歸為一體的 NVIDIA RTX 平台,包括:
- NVIDIA RTX 平台:包含所有圖靈功能的通用平台,包括進階著色器。
- NVIDIA RTX 光線追蹤技術:RTX 平台光線追蹤技術名稱。
- GameWorks Raytracing:光線追蹤降噪模組的 GameWorks SDK。
- GeForce RTX:使用 NVIDIA RTX 即時光線追蹤與遊戲相關的品牌。
- GeForce RTX:顯卡品牌。
NGX 技術上隸屬 RTX 平台,最具代表性的是 DLSS(深度學習超級取樣)技術。DLSS 使用專為遊戲而設的 DNN(深度神經網路),使用超高品質的 64 倍超級取樣影像或真實畫面訓練,進而透過 Tensor Core 推斷高品質的抗鋸齒結果。標準模式下,DLSS 以較低的匯入樣本推斷出高倍抗鋸齒的結果,在目標分析度可達到與 TAA 相似的效果。

由於涉及深度學習,NVIDIA 正在將純粹的計算/專業功能推向消費者領域。在圖靈上,Tensor Core 可加速 DLSS 等特徴,也可以加速某些基於 AI 的降噪器,以清理和校正即時光線追蹤算圖的畫面。
小結
圖靈架構和 Geforce RTX 發表,標誌了電腦圖形學在消費級市場開始從虛假視覺欺騙向真實追光逐影發展。到目前為止,業界的讚譽也毫不吝嗇。
雖然圖靈架構增設專屬光線追蹤單元 RT Core,並輔以 Tensor Core AI 降噪,但冷靜客觀的思考後,在 1080P 解析度,光線追蹤具備基本可用性的入門門檻是每格畫面包含 1 億條光線,如果以 60fps 為準,需要 GPU 達到每秒至少處理 60 億條光線的計算能力。
回過頭來看剛發表的 Geforce RTX 2080Ti / 2080 / 2070 三款顯卡,光線追蹤效能分別是每秒處理 100 億/80 億/60 億條光線,且 NVIDIA 似乎表示未來更低的 Geforce RTX / GTX 2060 等顯卡將不再支援光線追蹤。
不知這是不是巧合,Geforce RTX 2070 的光線追蹤效能剛好壓在上述具備基本可用性的入門門檻,這樣來看,更低端的顯卡不支援光線追蹤也情有可原。
此外,也許目前的光線追蹤演算法過於追求簡化,還原光影關係仍有可能出現錯誤。例如 NVIDIA 用《戰地風雲 5》示範 RTX 效果時,汽車車身反射火光便出現了一處錯誤,紅框處的車燈罩是背對車後火光,角度上來看完全不應該有火光反射:

根據最近流出的效能測試來看,即便是最高階的 Geforce RTX 2080Ti 開啟光線追蹤後,也僅能在 1080P 下維持格數在 45fps 左右,顯然大幅低於理論效能。種種情況表明,現階段的光線追蹤依然徘徊在「有可用性」的門檻邊緣,圖靈架構和 Geforce RTX 顯卡是否過了第一關,還真的不好說……





